In my head there is always a competition for which post is next and sometimes if there will be a post at all. ODBC and RevoScaleR have been arguing and its super annoying. ODBC was the last post, how you can connect to any version of SQL using just ODBC. If you did not go to the link I published, you can connect to Oracle, MySQL, PostgreSQL, SQLite too. The point of that will become much more clear when you start querying MSDB Job History so you can write your own R ggplot reports on job length and overlapping jobs (spoilers…). I will give you the code to get you started, later, maybe tomorrow, I don’t know yet depends on who wins the next argument. For now it is connect to SQL Server using RevoScaleR package…
If you read and followed the ODBC post and you successfully connected to and started running queries, you know a lot, you probably started pulling lots of data back, maybe you even crashed R Studio, if you did good for you. If not, what are you waiting for, it’s the new Excel! Query a bazillion rows until you take down a production server and get the Admins furious with you until they limit your account and ban R form the environment… Okay, maybe don’t do that, select top 100 is your friend… If you are the admin, someone is going download the db to their desktop, get ready.
To be fair, MSFT published all of this in the books online, it worked when they wrote it, not all of the code works anymore. If they wrote it and it works I will quote them, if it does not work I will show you a way around. Some of what I am going to be demoing builds on the end to end data science walk through for the NYC cab data, which I will get way more into at a later date. The walk through is slightly more interesting than watching grass grow, the likelihood of a cab driver getting a tip is not interesting to me, from a data analysis perspective it is interesting that a random sample of 1000 people picked up within .25 miles of MidTown, only 1 went to New Jersey… Why is that? Why statistically, do people who catch cabs in MidTown not go to New Jersey? There is also one fare in Bermuda, I’m really not sure how the cab got from NYC to Bermuda, when we get to that dataset and start playing I will call it out, its amusing to say the least.
When MSFT bought Revolution Analytics the point was to try and get deeper integration between statistical learning and machine learning technologies and SQL, to be fair that integration goes much farther than just SQL Server it is being looked across many products. That being said, MSFT is not new to the stat learning game, they have been doing it for a very long time internally and with Analysis Services which shipped with Data Mining. Would have been way cooler had MSFT named it SSAS Machine Learning tool kit back in 2000…
The Architecture for Revo is a bit clunkier that good old-fashioned ODBC, you can read all about it here, there are lots of moving parts, but this facility should open the flood gates of language integration with SQL. SQL 2016 supports R and SQL Server 2017 supports R and Python.
In the mean time wrap your brain around this call stack to get one R command into SQL and back…
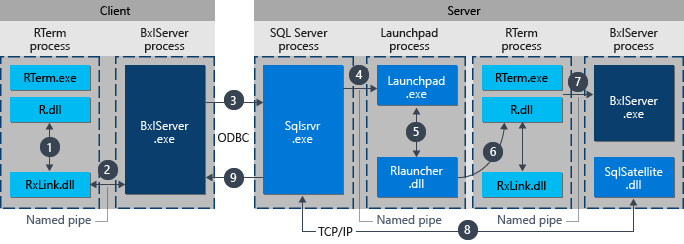
What we have today with RevoScaleR will connect to SQL Server 2016 or 2017. I did attempt a somewhat futile test to see what would happen if I tried to connect to a SQL Server 2012 instance but unfortunately the RevoScaR package had not been updated to support the one month old version of R I was using, ODBC did however work. I may try this again at a later date, but installing an entire environment just to test one connection to SQL 2012 is of little interest to me at this moment, I will how ever be doing it later on to back test some code. You can try it and let me know in the comments! 😀
# you only need to install the package once per machine
# unless there is an update to the package,
# be sure to look for errors in the console output
install.packages("RevoScaleR")
# library will load the package into memory and make it available for use
# This will need to be run every time R is started
library("RevoScaleR")
# Set the timezone,
# If you skip this step it will remind you later
Sys.setenv(TZ='GMT')
# If you have ever connected using odbc, this will look familiar
# build the connection string
# all of this is being loaded into variables to be passed into a function later
connStr <- "Driver=SQL Server; Server=DSVM1; Database=master;Trusted_Connection=Yes"
sqlShareDir <- paste("C:\\AllShare\\",Sys.getenv("USERNAME"),sep="")
sqlWait <- TRUE
sqlConsoleOutput <- TRUE
# Here is the function we are passing the variables into
# You can pass all of the above parameters in directly if you like
# ?RxInSqlServer to learn more
sqlcc <- RxInSqlServer(connectionString = connStr,
shareDir = sqlShareDir,
wait = sqlWait,
consoleOutput = sqlConsoleOutput)
# if you have more than one ODBC compute context created,
# which one do you want to use?
rxSetComputeContext(sqlcc)
# Load up a query
# Notice we can use select *, this will handle guids unlike ODBC
#sampleDataQuery <- "select * from sys.dm_exec_sessions"
# Just a query to test connectivity
sampleDataQuery <- "select @@version"
# prepare the instructions
inDataSource <- RxSqlServerData(
sqlQuery = sampleDataQuery,
connectionString = connStr,
rowsPerRead=500
)
# execute the query return the results to MyStuff
MyStuff<- rxImport(inData = inDataSource)
There are some really good reasons to use Revo over base R packages like odbc, one of which is the xdf files. XDF files, imagine an XDF file as column store table laid down to disk on write. If you have large amounts of data to pull back form SQL this will be the way to go, side by side on small datasets ODBC will be faster, but for large datasets RevoScaleR tools should be far superior. Once we start doodling with some real data i will demo xdf features.
My Versions today:
> version
_
platform x86_64-w64-mingw32
arch x86_64
os mingw32
system x86_64, mingw32
status
major 3
minor 3.3
year 2017
month 03
day 06
svn rev 72310
language R
version.string R version 3.3.3 (2017-03-06)
nickname Another Canoe
> packageVersion("RevoScaleR")
[1] ‘9.1.0’