So here you are, you know SQL or you at least do something with it everyday and are wondering what all the hoopla is about R and data science. Lets break down the first barrier, R and data science actually have little to do with each other, R is a language, data science is an abstract field of work, sort of like saying I am a computer scientist, that will narrow it down but not by much. What is your industry, what languages do you use, what is your education, hacker, bachelors, masters, phd…? You can be a Data Scientist and never use R.
But we are going to use R, today, right now, get ready.
I have done prior posts about my environment, I will not bore you with the details, just know that I am using a Data Science Virtual Machine in Azure, mostly because I am lazy and don’t want to build my own any more, its worth a few bucks a month to me for someone else to host all this crap and take care of setup and updates for me.
To get us started, I have R from CRAN installed, if you don’t, go do it, there are dozens of videos and blogs on how to. Here is one for R! and, Here is one for RStudio!
I have R Studio installed, it is just the IDE for R, Imagine R Studio as the Management Studio to R. If you are old school and hate yourself you can do everything via command line using the Base R gui too.
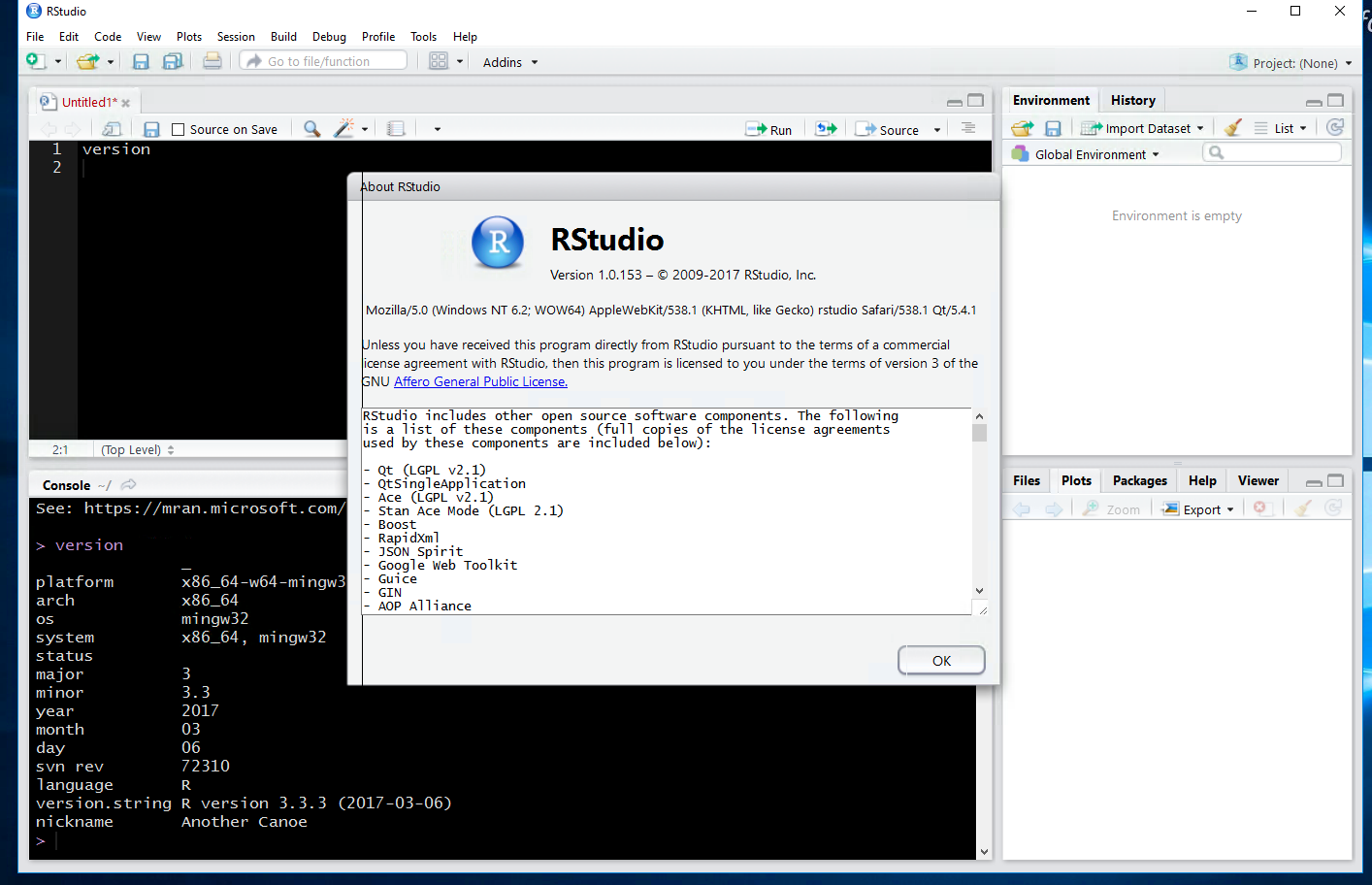
You can see my R version from the R command “version”, and the R Studio version from About RStudio, as we go forward I will try to share the package versions and the R and R studio version, with this many moving parts breaking something is really easy. With that in mind, if you ever update R, RStudio, or a package and something stops working, you can bet it is related to an update somewhere. As annoying as it can be, don’t be afraid to stay 2 or 3 versions behind on R or and RStudio, unless you have unlimited time, then by all means install pre-prod code directly from github, i will discuss that later.
In the title of the post it states “Regardless of SQL Version”, for this we are going to use a package called ODBC, it simply uses the ODBC on your machine to connect to SQL, and if you have other odbcs unrelated to SQL you can connect to those databases as well. While SQL Server requires Revo packages to call out to R and back in and a SQL version of 2016 or higher, connecting to SQL from R does not require Revolution packages or tools or the SQL Launcher and does not require a specific version of SQL. The link above goes into the nasty details of DBI, RODBC and RODBCDBI, its an interesting read, i suppose, its basically telling you how awesome odbc is. I say we accept that fact and move on. BTW, if you ever need help on an R command, just put a question mark in front of it, like; ?odbc or ?version in teh R Console.
To be clear, if you are doing some big data crunching there are benefits to using Revolution packages and tools, and we will get into that at a way later date, but not today, today we just connect R to a SQL Server of any version.
Create a new R Script file to get you started, start saving them…
Lets start with something simple, connect to any version of SQL using ODBC.
#you only need to install the package once per machine
#unless there is an update to the package,
#be sure to look for errors in the console output
install.packages("odbc")
# library will load the package into memory and make it available for use
# This will need to be run every time R is started
library(odbc)
# ODBC requires the timezone to be set,
# If you skip this step it will remind you
Sys.setenv(TZ='GMT')
# If you have ever connected using odbc, this will look familiar
# build the connection
master <- dbConnect(odbc::odbc(),
Driver = "SQL Server",
Server = "localhost",
Database = "master",
Trusted_Connection = 'Yes')
# prepare a sql statement to send
SQLStmt <- sprintf("SELECT [session_id]
,[login_time]
,[host_name]
,[program_name]
FROM [master].[sys].[dm_exec_sessions]")
# Alternatively, you can run @@version, just to connect and get out
# SQLStmt <- sprintf("select @@version")
# Submit the query, if your syntax is wrong this is where you will see it the error
rs <- dbSendQuery(master, SQLStmt)
# Receive the results into a data frame called MyStuff
MyStuff <- dbFetch(rs)
# house keeping
dbClearResult(rs)
dbDisconnect(master)
If you received no errors you should now have a dataframe called MyStuff that has some number of rows and 4 columns, you will notice that R calls these observations (rows), and variables (columns). This is leftover from the statistical language of a study, a case is an observation or a row to you and me, and a variable is a column.
If you change the query to Select * from sys].[dm_exec_sessions], and receive the error, “nanodbc.cpp:3102: 07009: [Microsoft][ODBC SQL Server Driver]Invalid Descriptor Index”, in the case of this query it is because the tidyverse odbc has some difficulty with guids, so, take the guids in the query and cast them as varchar(32) and you will get past it(“cast([original_security_id] as varchar(36))”). Yes, you will have to blow out the entire column list and find all of the guids, but then again you should not be using select * anyway, or so people tell me. 😛
My Versions today:
> version
_
platform x86_64-w64-mingw32
arch x86_64
os mingw32
system x86_64, mingw32
status
major 3
minor 3.3
year 2017
month 03
day 06
svn rev 72310
language R
version.string R version 3.3.3 (2017-03-06)
nickname Another Canoe
> packageVersion("odbc")
[1] ‘1.0.1’
## If you ran "select @@version"
> MyStuff
1 Microsoft SQL Server 2016 (SP1-CU1) (KB3208177) - 13.0.4411.0 (X64) \n\tJan 6 2017 14:24:37 \n\tCopyright (c) Microsoft Corporation\n\tDeveloper Edition (64-bit) on Windows Server 2016 Datacenter 6.3 (Build 14393: ) (Hypervisor)\n