So a copy of this will live on my github site as well, the blog post of the jupyter notebook is mostly to see if wordpress crashes 😀
Continue readingAuthor Archives: shep2010
Random Forest with the EPA Mpg dataset
Published August 31, 2018 / by shep2010
This is a Random Forest Regression of the EPA Dataset i wrote on few posts back. This is more of a log drawn out doodle, but you can recreate it if you like, all of my data is available.
Logistic Regression 5, train, test, predict
Published August 24, 2018 / by shep2010The last in this series is splitting the the data into train and test then attempt a prediction with the test data set. It is possible to do this early in the process, but no harm in waiting as long as you do it eventually.
First off once again lets load the data. Notice i have added a new package for splitstackshape which provides a method to stratify the data.
If you are more interested in Python i have created a notebook using the same dataset but with the python solution here.
Logistic Regression 4, evaluate the model
Published August 23, 2018 / by shep2010In Logistic Regression 3 we created a model, quite blindly i might add. What do i mean by that? I spent a lot of time getting the single data file ready and had thrown out about 50 variables that you never had to worry about. If you are feeling froggy you can go to the census and every government website to create your own file with 100+ variables. But, sometimes its more fun to tale your data and slam it into a model and see what happens.
What still needs done is to look for colliniearity in the data, in the last post i removed the RUC variables form the model since the will change exactly with the population, the only thing they may add value to is if i wanted to use a factor for population vs. the actual value.
If you are more interested in Python i have created a notebook using the same dataset but with the python solution here.
Logistic Regression 3, the model
Published August 22, 2018 / by shep2010 / 1 Comment on Logistic Regression 3, the modelWoo Hoo here we go, in this post we will predict a president, sort of, we are going to do it knowing who the winner is so technically we are cheating. But, the main point is to demonstrate the model not the data. The ISLR has an great section on Logistic Regression, though i thing the data chose was terrible. I would advise walking through it then finding a dataset that has a 0 or 1 outcome. Stock market data for models sucks, i really hate using it and really try to avoid it.
Logistic Regression 2, the graphs
Published August 21, 2018 / by shep2010I should probably continue the blog where I mentioned i would write about Logistic Regression. I have been putting this off for a while as i needed some time to pass between a paper my college stats team and I submitted and this blog post. Well, here we are. This is meant to demonstrate Logistic Regression, nothing more, i am going to use election data because it is interesting, not because i care about proving anything. Census data, demographics, maps, election data are all interesting to me, so that makes it fun to play with.

Consolidated Reference of Machine Learning Applications – Retail
Published August 16, 2018 / by shep2010Continuing the prior post, we are moving on to Retail. Woo Hoo. As i stated in the prior blog; This came out of at Fast.ai ppt that can be found here. Granted they only provided the list.
This post will be made of a lot of quotes and references, that is kind of the point, very little original content will come from me as I am not the creator of much data science, just a user of it, though i am sure i will add commentary especially in retail as i have some practical experience in a few areas.
The funny thing about solving a data science problem is that their are many ways to solve it, so i don’t expect this to be 100% comprehensive, i try to find what appears to be a canonical solution, though that does not mean you cannot stuff everything into a neural net and close your eyes, which is what everyone appears to be doing these days…
Consolidated Reference of Machine Learning Applications – Marketing
Published August 11, 2018 / by shep2010Though some of these are actually optimization…
This came out of at Fast.ai ppt that can be found here. Granted they only provided the list. You will notice an ethics deck they have uploaded as well, I encourage you to review at it. I have a few ethics slides in my data science talk, but the fast.ai gang hit way harder than I typically do. I admit, shock is a good way to wake people into thinking about what they are doing.
In their ML Applications deck they have a list of applications by industry, below I have them listed out and what I hope is to present either an elevator pitch of what each one is, or and executive overview of each and links to more info. This post will be made of a lot of quotes and references, that is kind of the point, no original content will come from me as I am not the creator of much data science, just a user of it, though i am sure i will add commentary. This will be a series of blogs posts, and clearly each post has the potential for being very long even with just a brief summary and a few links.
The funny thing about solving a data science problem is that their are many ways to solve it, so i don’t expect this to be 100% comprehensive, i try to find what appears to be a canonical solution, though that does not mean you cannot stuff everything into a neural net and close your eyes, which is what everyone appears to be doing these days…
Enjoy
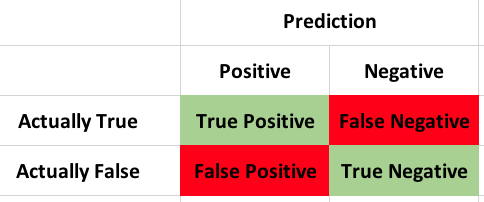
Make It a More Confusing Matrix, Please!
Published May 14, 2018 / by shep2010If the title of the thing you are using is called confusion, stop and start over. Never will you need more proof that statistics is deliberately screwing with you and trying to keep you away until you disassemble a confusion matrix. In lieu of the name, lets give it some new names;
Bewilderment matrix, disorientation matrix, agitation matrix, befuddling matrix, perplexity matrix, i think you get the point…
So what it is it? From an Azure ML classification i am working on, lets take a look at just a tiny bit of it.

Python Word Cloud and NLTK
Published March 7, 2018 / by shep2010 / 3 Comments on Python Word Cloud and NLTKThis post was certainly not meant to be next, but here it is. I am working on a project that may very well take me a year to complete maybe longer depending on demands. I am also taking this blog into python which was not meant to happen for a while as i would like to get every R post in this blog mirrored with python as well.
